Random Access Control in NB-IoT with Model-Based Reinforcement Learning
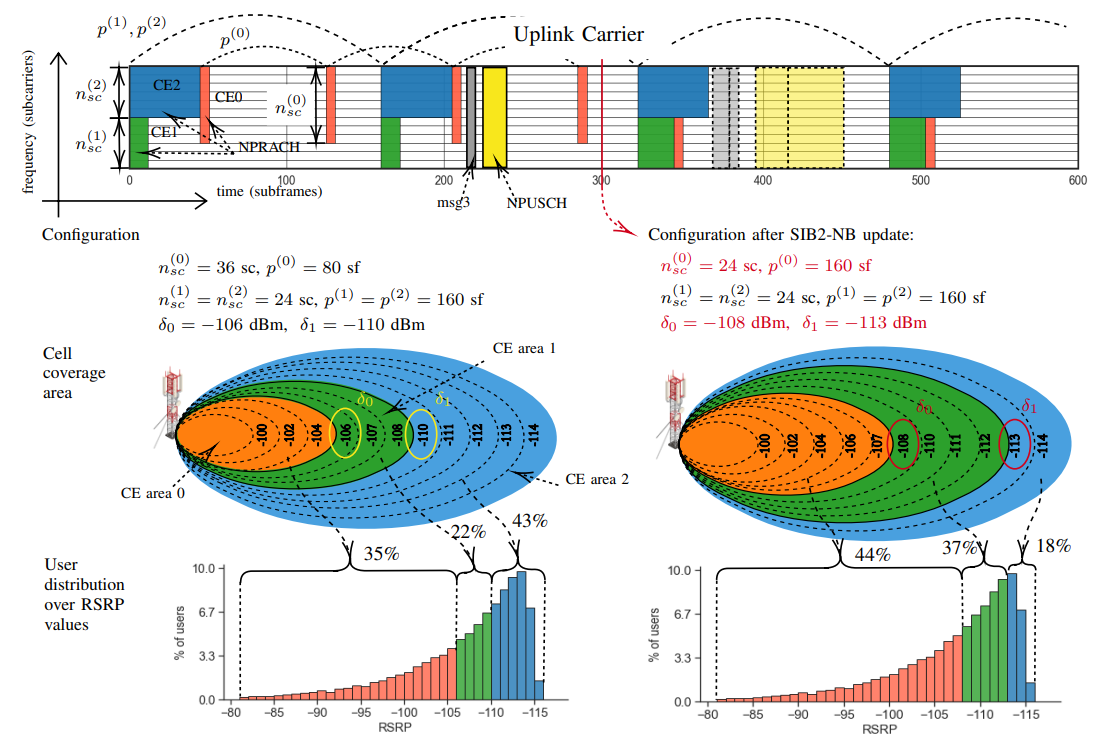
In NB-IoT, the cell can be divided into up to three coverage enhancement (CE) levels, each associated with a narrowband Physical Random Access Channel (NPRACH) that has a CE level-specific configuration. Providing resources to NPRACHs increases the success rate of the random access procedure but detracts resources from the uplink carrier for other transmissions. To effectively address this trade-off we propose to adjust the NPRACH parameters along with the power thresholds that determine the CE levels, which allows to control at the same time the traffic distribution between CE levels and the resources allocated to each CE level. Since the traffic is dynamic and random, reinforcement learning (RL) is a suitable approach for finding an optimal control policy, but its inherent sample inefficiency is a drawback for online learning in an operational network. To overcome this issue, we propose a new model-based RL algorithm that achieves high efficiency even in the early stages of learning.
Random Access Control in NB-IoT with Model-Based Reinforcement Learning Read More »